6 Monte Carlo Sampling#
With Monte Carlo sampling, also referred to as parametric bootstrap, the probabiliy distribution of model parameters is approximated by generating a large number of artificial measurements (resampling) and re-estimating model parameters for each.
For a detailed description of the method the interested reader is referred to:
from estim8.models import FmuModel
from estim8 import visualization, datatypes, Estimator
from estim8.error_models import LinearErrorModel
import pandas as pd
6.1 Load the model#
SimpleBatchModel = FmuModel(path='../../../tests/test_data/SimpleBatch.fmu')
6.2 Import experimental data & create an Experiment object#
Per default, estim8 assumes normally distributed measurement noise, e.g. using the LinearErrorModel introduced in Notebook 2. Experimental data and error modeling.
data = pd.read_excel(r'SimpleBatch_Data.xlsx', index_col=0, header=(0, 1))
data.columns = data.columns.droplevel(1)
print(data.head())
# use a linear error model with normally distributed noise
experiment = datatypes.Experiment(data, error_model=LinearErrorModel(slope=0.05, offset=0.1))
Time X S
0.0 0.176200 NaN
0.1 0.318313 NaN
0.2 0.285270 NaN
0.3 0.218600 NaN
0.4 0.248210 NaN
6.3 Defining the estimation problem & create Estimator object#
As described in Notebook 3. Parameter estimation, unknown parameters and their bounds are defined and an Estimator instance is created.
## define unknown parameters with upper and lower bounds
bounds = {
'X0': [0.05, 0.15],
'mu_max': [0.1, 0.9],
'Y_XS': [0.1, 1]
}
# create an estimator object
estimator = Estimator(
model=SimpleBatchModel,
bounds=bounds,
data=experiment,
t=[0, 10, 0.1],
metric="negLL"
)
6.4 Start Monte Carlo Sampling#
Monte carlo sampling runs an optimization for each generated sample, therefore the method provides the same arguments and keyword arguments as a single estimation job using the Estimator’s estimate method:
Argument |
Type |
Description |
|---|---|---|
method |
str or List[str] |
the method key of the optimization algorithm. Pygmo algorithms are passed as a List[str] |
max_iter |
int |
maximum iteration rounds for the solver algorithm per estimation job. |
Kwarg |
Type |
Description |
n_jobs |
int |
number of parallel jobs to run the optimization algorithm with for each estimation job |
optimizer_kwargs |
dict |
Keyword arguments for the optimization function |
Additional arguments and keyword arguments for the mc_sampling method are:
Kwarg |
Type |
Description |
|---|---|---|
n_samples |
int |
The number of Monte Carlo samples |
mcs_at_once |
int |
number of Monte carlo estimations run in parallel |
optimizer_kwargs |
dict |
keyword arguments for the optimization function |
⚠️ This method puts considerable amount of work on your machine!
mc_samples = estimator.mc_sampling(
method='de',
max_iter=1000, # maximum iterations for each estimation run
n_jobs=1, # parallelization of each estimation run
mcs_at_once=6, # number of Monte Carlo estimations to run in parallel
n_samples=300 # number of monte carlo samples
)
---- Sample 1 completed
---- Sample 2 completed
---- Sample 3 completed
---- Sample 4 completed
---- Sample 5 completed
---- Sample 6 completed
---- Sample 7 completed
---- Sample 8 completed
---- Sample 9 completed
---- Sample 10 completed
---- Sample 11 completed
---- Sample 12 completed
---- Sample 13 completed
---- Sample 14 completed
---- Sample 15 completed
---- Sample 16 completed
---- Sample 17 completed
---- Sample 18 completed
---- Sample 19 completed
---- Sample 20 completed
---- Sample 21 completed
---- Sample 22 completed
---- Sample 23 completed
---- Sample 24 completed
---- Sample 25 completed
---- Sample 26 completed
---- Sample 27 completed
---- Sample 28 completed
---- Sample 29 completed
---- Sample 30 completed
---- Sample 31 completed
---- Sample 32 completed
---- Sample 33 completed
---- Sample 34 completed
---- Sample 35 completed
---- Sample 36 completed
---- Sample 37 completed
---- Sample 38 completed
---- Sample 39 completed
---- Sample 40 completed
---- Sample 41 completed
---- Sample 42 completed
---- Sample 43 completed
---- Sample 44 completed
---- Sample 45 completed
---- Sample 46 completed
---- Sample 47 completed
---- Sample 48 completed
---- Sample 49 completed
---- Sample 50 completed
---- Sample 51 completed
---- Sample 52 completed
---- Sample 53 completed
---- Sample 54 completed
---- Sample 55 completed
---- Sample 56 completed
---- Sample 57 completed
---- Sample 58 completed
---- Sample 59 completed
---- Sample 60 completed
---- Sample 61 completed
---- Sample 62 completed
---- Sample 63 completed
---- Sample 64 completed
---- Sample 65 completed
---- Sample 66 completed
---- Sample 67 completed
---- Sample 68 completed
---- Sample 69 completed
---- Sample 70 completed
---- Sample 71 completed
---- Sample 72 completed
---- Sample 73 completed
---- Sample 74 completed
---- Sample 75 completed
---- Sample 76 completed
---- Sample 77 completed
---- Sample 78 completed
---- Sample 79 completed
---- Sample 80 completed
---- Sample 81 completed
---- Sample 82 completed
---- Sample 83 completed
---- Sample 84 completed
---- Sample 85 completed
---- Sample 86 completed
---- Sample 87 completed
---- Sample 88 completed
---- Sample 89 completed
---- Sample 90 completed
---- Sample 91 completed
---- Sample 92 completed
---- Sample 93 completed
---- Sample 94 completed
---- Sample 95 completed
---- Sample 96 completed
---- Sample 97 completed
---- Sample 98 completed
---- Sample 99 completed
---- Sample 100 completed
---- Sample 101 completed
---- Sample 102 completed
---- Sample 103 completed
---- Sample 104 completed
---- Sample 105 completed
---- Sample 106 completed
---- Sample 107 completed
---- Sample 108 completed
---- Sample 109 completed
---- Sample 110 completed
---- Sample 111 completed
---- Sample 112 completed
---- Sample 113 completed
---- Sample 114 completed
---- Sample 115 completed
---- Sample 116 completed
---- Sample 117 completed
---- Sample 118 completed
---- Sample 119 completed
---- Sample 120 completed
---- Sample 121 completed
---- Sample 122 completed
---- Sample 123 completed
---- Sample 124 completed
---- Sample 125 completed
---- Sample 126 completed
---- Sample 127 completed
---- Sample 128 completed
---- Sample 129 completed
---- Sample 130 completed
---- Sample 131 completed
---- Sample 132 completed
---- Sample 133 completed
---- Sample 134 completed
---- Sample 135 completed
---- Sample 136 completed
---- Sample 137 completed
---- Sample 138 completed
---- Sample 139 completed
---- Sample 140 completed
---- Sample 141 completed
---- Sample 142 completed
---- Sample 143 completed
---- Sample 144 completed
---- Sample 145 completed
---- Sample 146 completed
---- Sample 147 completed
---- Sample 148 completed
---- Sample 149 completed
---- Sample 150 completed
---- Sample 151 completed
---- Sample 152 completed
---- Sample 153 completed
---- Sample 154 completed
---- Sample 155 completed
---- Sample 156 completed
---- Sample 157 completed
---- Sample 158 completed
---- Sample 159 completed
---- Sample 160 completed
---- Sample 161 completed
---- Sample 162 completed
---- Sample 163 completed
---- Sample 164 completed
---- Sample 165 completed
---- Sample 166 completed
---- Sample 167 completed
---- Sample 168 completed
---- Sample 169 completed
---- Sample 170 completed
---- Sample 171 completed
---- Sample 172 completed
---- Sample 173 completed
---- Sample 174 completed
---- Sample 175 completed
---- Sample 176 completed
---- Sample 177 completed
---- Sample 178 completed
---- Sample 179 completed
---- Sample 180 completed
---- Sample 181 completed
---- Sample 182 completed
---- Sample 183 completed
---- Sample 184 completed
---- Sample 185 completed
---- Sample 186 completed
---- Sample 187 completed
---- Sample 188 completed
---- Sample 189 completed
---- Sample 190 completed
---- Sample 191 completed
---- Sample 192 completed
---- Sample 193 completed
---- Sample 194 completed
---- Sample 195 completed
---- Sample 196 completed
---- Sample 197 completed
---- Sample 198 completed
---- Sample 199 completed
---- Sample 200 completed
---- Sample 201 completed
---- Sample 202 completed
---- Sample 203 completed
---- Sample 204 completed
---- Sample 205 completed
---- Sample 206 completed
---- Sample 207 completed
---- Sample 208 completed
---- Sample 209 completed
---- Sample 210 completed
---- Sample 211 completed
---- Sample 212 completed
---- Sample 213 completed
---- Sample 214 completed
---- Sample 215 completed
---- Sample 216 completed
---- Sample 217 completed
---- Sample 218 completed
---- Sample 219 completed
---- Sample 220 completed
---- Sample 221 completed
---- Sample 222 completed
---- Sample 223 completed
---- Sample 224 completed
---- Sample 225 completed
---- Sample 226 completed
---- Sample 227 completed
---- Sample 228 completed
---- Sample 229 completed
---- Sample 230 completed
---- Sample 231 completed
---- Sample 232 completed
---- Sample 233 completed
---- Sample 234 completed
---- Sample 235 completed
---- Sample 236 completed
---- Sample 237 completed
---- Sample 238 completed
---- Sample 239 completed
---- Sample 240 completed
---- Sample 241 completed
---- Sample 242 completed
---- Sample 243 completed
---- Sample 244 completed
---- Sample 245 completed
---- Sample 246 completed
---- Sample 247 completed
---- Sample 248 completed
---- Sample 249 completed
---- Sample 250 completed
---- Sample 251 completed
---- Sample 252 completed
---- Sample 253 completed
---- Sample 254 completed
---- Sample 255 completed
---- Sample 256 completed
---- Sample 257 completed
---- Sample 258 completed
---- Sample 259 completed
---- Sample 260 completed
---- Sample 261 completed
---- Sample 262 completed
---- Sample 263 completed
---- Sample 264 completed
---- Sample 265 completed
---- Sample 266 completed
---- Sample 267 completed
---- Sample 268 completed
---- Sample 269 completed
---- Sample 270 completed
---- Sample 271 completed
---- Sample 272 completed
---- Sample 273 completed
---- Sample 274 completed
---- Sample 275 completed
---- Sample 276 completed
---- Sample 277 completed
---- Sample 278 completed
---- Sample 279 completed
---- Sample 280 completed
---- Sample 281 completed
---- Sample 282 completed
---- Sample 283 completed
---- Sample 284 completed
---- Sample 285 completed
---- Sample 286 completed
---- Sample 287 completed
---- Sample 288 completed
---- Sample 289 completed
---- Sample 290 completed
---- Sample 291 completed
---- Sample 292 completed
---- Sample 293 completed
---- Sample 294 completed
---- Sample 295 completed
---- Sample 296 completed
---- Sample 297 completed
---- Sample 298 completed
---- Sample 299 completed
---- Sample 300 completed
6.5 Evaluation of Monte Carlo Sampling#
For further evaluation and saving the sampling results e.g. to an Excel-file, the Monte Carlo samples mc_samples are stored in a pandas.DataFrame. This dataframe can then be passed to the different evaluation plot methods provided by the visualization submodule.
samples = pd.DataFrame(data = [elem[0] for elem in mc_samples]) # extract the parameter - estimate dictionary frome each sample and create a pandas DataFrame
samples.index.name = 'sample'
samples.head()
| X0 | mu_max | Y_XS | |
|---|---|---|---|
| sample | |||
| 0 | 0.086779 | 0.514876 | 0.493391 |
| 1 | 0.094593 | 0.506151 | 0.498500 |
| 2 | 0.087864 | 0.515612 | 0.497193 |
| 3 | 0.104462 | 0.491988 | 0.489170 |
| 4 | 0.089755 | 0.512506 | 0.502189 |
6.5.1 Forward simulation plot of Monte Carlo samples#
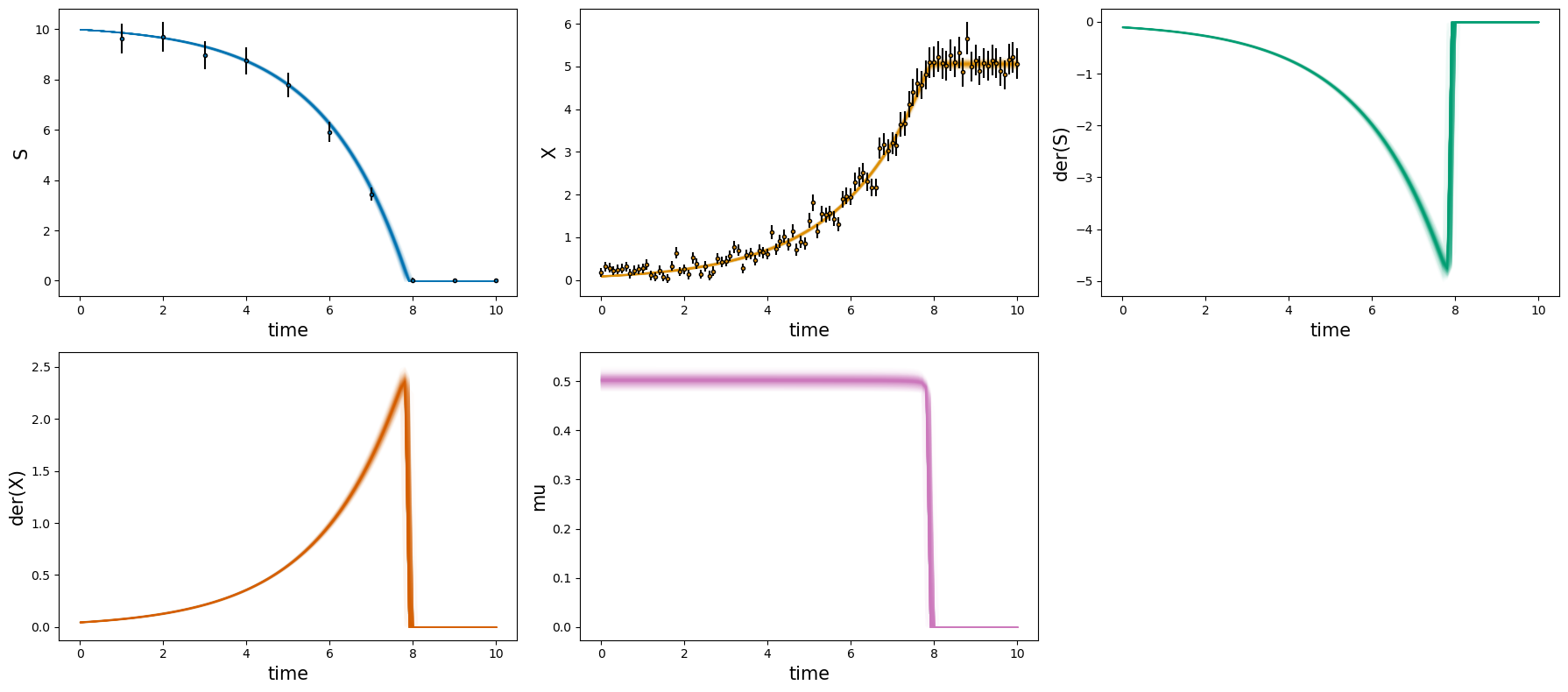
The first step when evaluating the sampling result should be a “posterior check”. For this matter, the plot_estimates method shows the density of resulting model predictions compared to experimental data.
# forward simulations
_ = visualization.plot_estimates_many(mc_samples=samples, estimator=estimator)
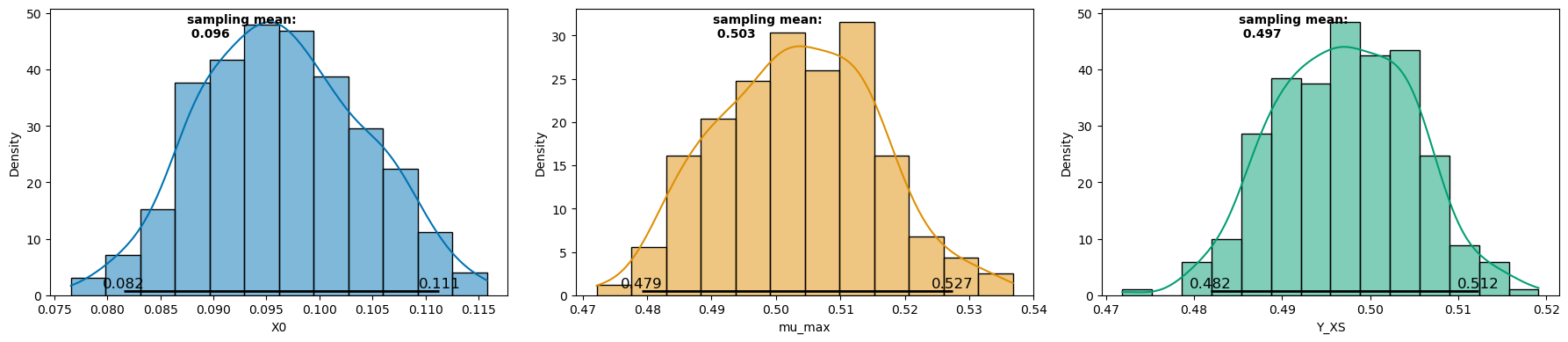
6.5.2 Parameter distributions#
The plot_distributions method can then be used to plot the parameter distributions via histograms along with statistical metrics of sampling mean and confidence interval ( 95 % in the example below).
_ = visualization.plot_distributions(samples, ci_level=0.95)
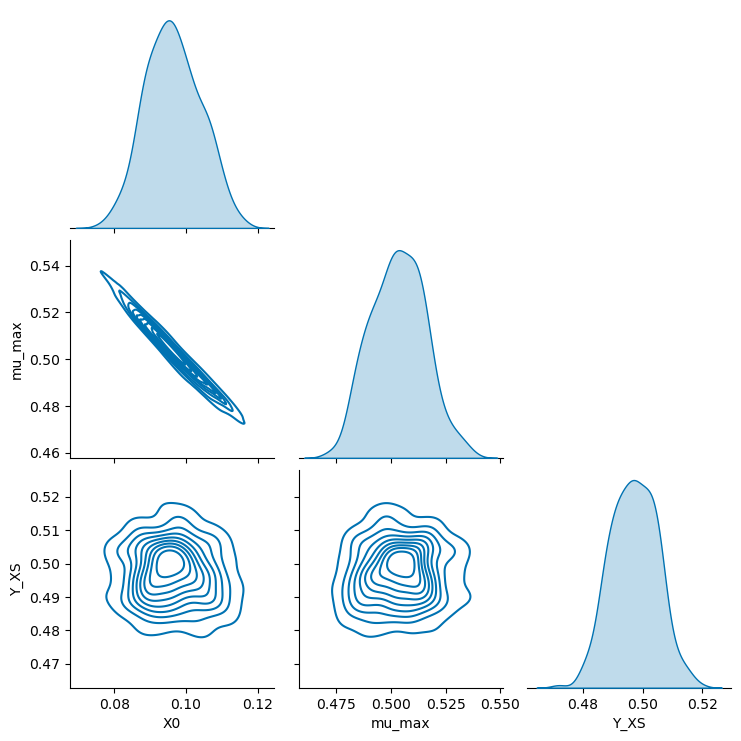
6.5.3 Pair plots#
Finally, parameter correlations can be revealed using the plot_pairs method.
_ = visualization.plot_pairs(samples, kind="kde")
6.6 Custom distributions#
There are many possible distributions to describe measurement errors. Therefore, the use of any scipy.stats.rv_continuous distribution is enabled. For more information, please check out the section 3.2.3 Custom error models in Notebook 2.